

Abstract
We propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o.
Method
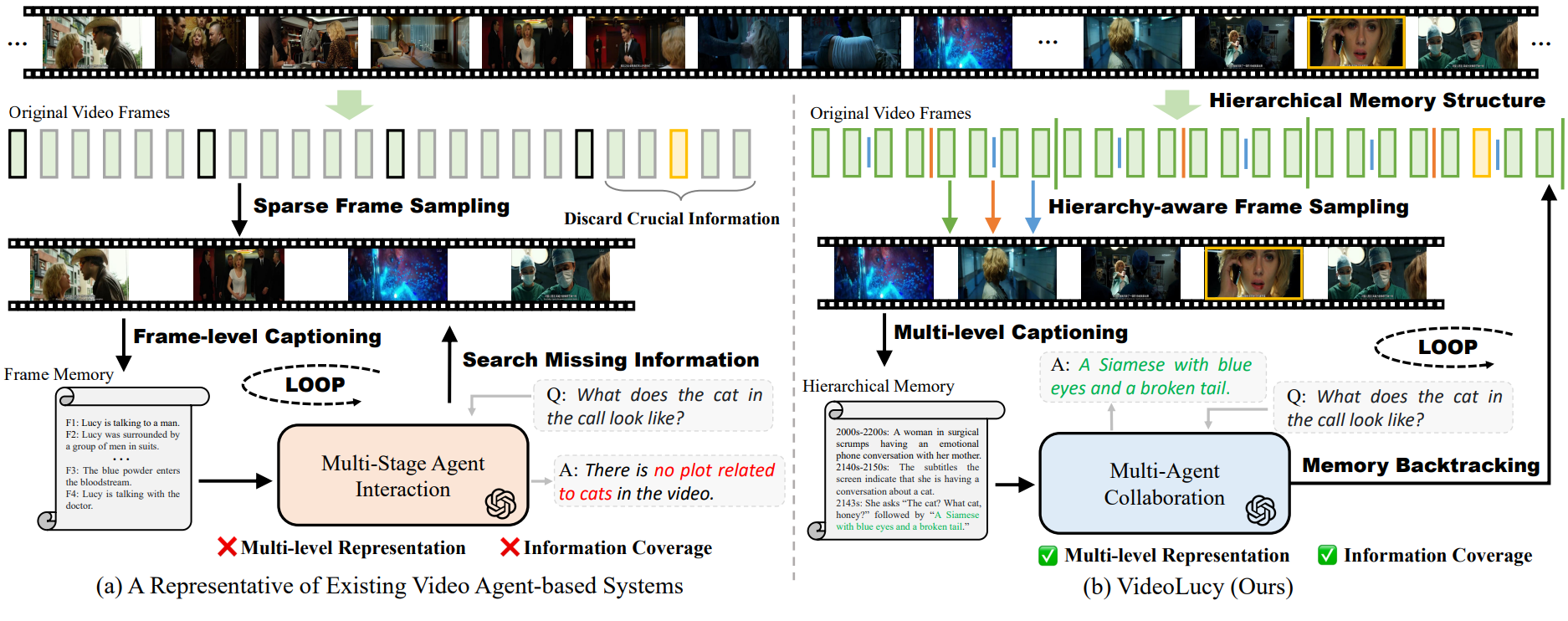
Comparison between our VideoLucy with existing video agent-based systems. In(a), they usually perform frame-level captioning on sparsely sampled frames, and then search for information, resulting in great information loss and hampering temporal understanding. In (b), our VideoLucy, through a hierarchical memory structure and a memory backtracking mechanism, effectively performs multi-level video representation and achieves comprehensive information coverage.

We propose a novel iterative backtracking mechanism. Through an agent-driven iterative loop, we continuously update the current memory initialized by sparse coarse memory, so as to dynamically explore the question-related memory in terms of both breadth and depth. This mechanism emulates the human recollection process and achieves a comprehensive search and integration of information relevant to the question with a relatively low resource cost.
EgoMem Benchmark

We construct a new benchmark for ultra-long video understanding, namely EgoMem, aiming to measure the ability to model instantaneous (detail perception) and continuous (event understanding) memory of long videos. Based on the video resources of EgoLife, we manually annotate question-answer pairs that particularly focus on the understanding of cross-temporal events and the perception of instantaneous visual features for each day’s long video. For the event understanding, we design six different question types to conduct a comprehensive and effective evaluation of the model’s performance in a real sense, and to avoid shortcuts. In addition, we manually annotate questions about the subtle visual features in those instantaneous time segments to assess whether the model can effectively cover detailed information. It contains 42 videos with an average duration of 6.33 hours and 504 questions.
This is a clip from the original long video, provided as a demo.
An example for the Detail Perception task in EgoMem:
Jake picked up KFC fast food from the delivery person for lunch. What was the delivery person wearing when Jake received the food?
A. A blue denim jacket, a blue-green long dress, and white sports shoes.
B. A light green long-sleeved shirt, black long pants, and black leather shoes.
C. A green long-sleeved jacket, black long pants, and white sports shoes.
D. An orange-gray T-shirt, khaki loose long pants, and gray sports shoes.
Reanson: Around 3 seconds before and after 14:09:41, when Jake picked up the food from the delivery person, the delivery person was wearing a green long-sleeved jacket, black long pants, and white sports shoes.
Needle-in-A-Video-Haystack
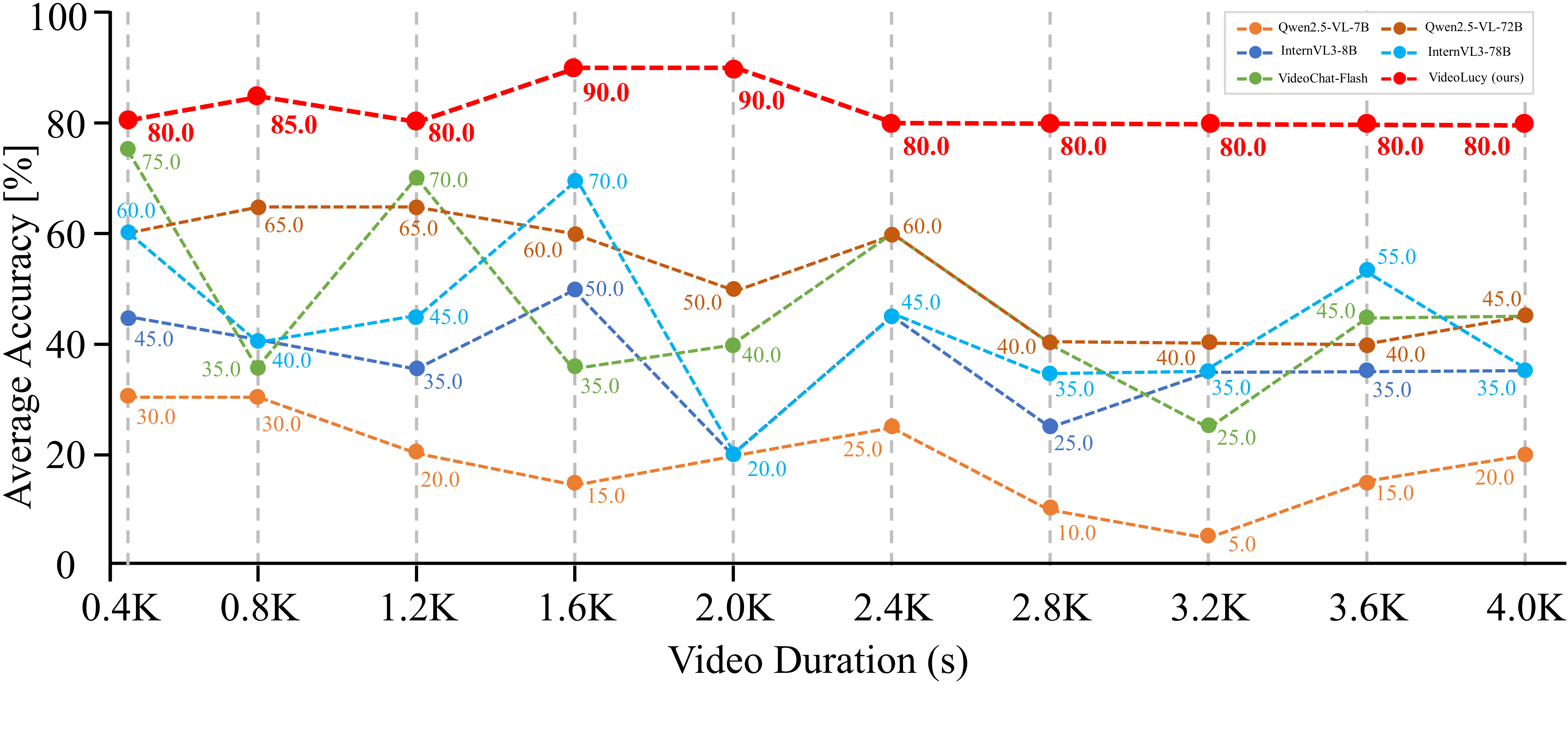
We conduct a Needle-in-A-Video-Haystack evaluation experiment. Specifically, we randomly select 10 long videos with durations ranging from 400s to 4000s from the existing benchmarks. Then, we insert 10s short video clips (needles) from the Internet at five arbitrary timestamps throughout each long video, from the beginning to the end. Then we feed the entire long video into the model and conduct a question-answering test regarding the content of these short clips. There are 4 questions for each clip, forming 20 questions for one long video. The performance of our VideoLucy is significantly better than that of the existing leading models, and its results are almost unaffected by the video length. This indicates that our VideoLucy has a very strong ability to search for question-relevant details in long video understanding. More experiments and details can be found in the paper.
A short scene appears in the video where an animal doll performs on a magnificent stage.
1. What kind of animal doll is the main performer in this scene?
A. Giraffe B. Tiger C. Gorilla D. Zebra
2. What musical instrument is being played?
A. Violin B. Guitar C. Piano D. Saxophone
3. What color of clothes is it wearing?
A. A dark brown leather coat and a green inner garment. B. A blue leather coat and a green inner garment.
C. A dark brown leather coat and a blue inner garment. D. A blue leather coat and a blue inner garment.
4. What is written on the plaque hanging above the stage?
A. sing on tour. B. animal show. C. dancing show. D. song and piano.
A short scene of a basketball game appears in the video.
1. What is the jersey number of the player with the ball on offense?
A. 6 B. 16 C. 23 D. 77
2. What color of sneakers is the player with the ball on offense wearing?
A. Pink B. Blue C. Black D. White
3. What kind of medal are the four players in the photo holding?
A. Bronze medal B. Silver medal C. Gold medal D. They are not holding any medal
4. What brand of sports jacket are the four players in the photo wearing?
A. Nike B. Adidas C. Puma D. Under Armour
A short scene appears in the video, in which a man dressed in ancient costume is sitting on the ground and looking into a mirror.
1. When the man looks at his feet, how many moles are there on his feet unexpectedly?
A. 1 B. 2 C. 3 D. 4
2. What style of shoes is the man wearing?
A. One foot is bare and the other foot is wearing a straw sandal. B. Wearing a pair of casual sports shoes.
C. One foot is bare and the other foot is wearing a sports shoe. D. Both feet are not wearing any shoes.
3. What style of pants is the man wearing?
A. Dark gray long pants decorated with red flowers. B. Dark gray long pants decorated with orange flowers.
C. White long pants decorated with red flowers. D. Pure gray long pants.
4. What does the man see in the mirror?
A. The Monkey King B. Zhu Bajie C. Sha Heshang D. Tang Seng.
A short live news report about a snooker match appears in the video.
1. Who is reported to have won the championship in this scene?
A. Zhao Xintong B. Ding Junhui C. Ronnie O'Sullivan D. Judd Trump
2. What is the time of the news broadcast in this scene?
A. May 6th B. May 7th C. May 8th D. May 9th
3. What color of ball is the snooker player hitting in this scene?
A. Black ball B. Pink ball C. Blue ball D. Green ball
4. What color of clothes is the winning player wearing in this scene?
A white long-sleeved shirt with a black sleeveless waistcoat. B. A black long-sleeved shirt with a white sleeveless waistcoat.
C. Just a white long-sleeved shirt. D. Just a black long-sleeved shirt.
A scene appears in the video, in which an elderly man standing beside a truck is having a conversation with a shirtless man.
1. What does the old man ask the young man to do?
A. Ask the young man to lend him money. B. Ask the young man to help collect the rent.
C. Ask the young man to pay the rent. D. Pay the rent for the young man.
2. What color of hat is the young man wearing?
A. Black B. Gray C. Not wearing a hat D. Green
3. What are the names of the two of them?
A. Brian and Jason B. Bob and Jack C. Rocky and Jack D. Trump and Bob
4. What does the shirtless young man do after the conversation?
A. He opens the door and walks into the room. B. He goes down the stairs.
C. He drives away. D. He jumps off the balcony.
Paper
BibTeX
@inproceedings{
zuo2025videolucy,
title={VideoLucy: Deep Memory Backtracking for Long Video Understanding},
author={Jialong Zuo, Yongtai Deng, Lingdong Kong, Jingkang Yang, Rui Jin, Yiwei Zhang, Nong Sang, Liang Pan, Ziwei Liu, Changxin Gao},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year={2025}
}